
Hash(해시)?
- 해시는 입력된 데이터를 고정된 길이의 데이터로 변환 값을 말한다.
- 데이터를 효율적으로 관리하기 위해, 임의의 길이 데이터를 고정된 길이의 데이터로 매핑하는 것
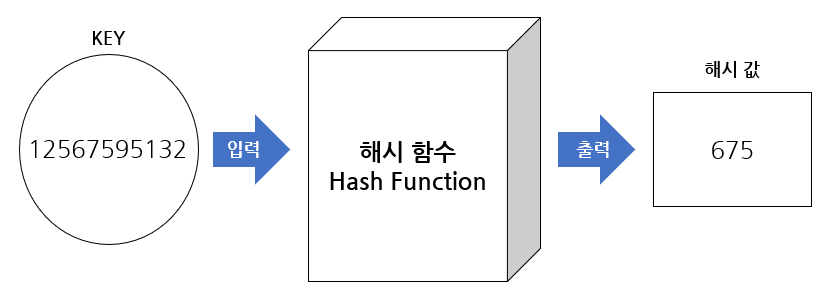
- 해시 함수를 구현하여 데이터 값을 해시 값으로 매핑한다.
- 데이터가 많아지면, 다른 데이터가 같은 해시 값으로 충돌나는 현상이 발생함
- collision 현상
- 정수로 변환된 해시는 배열의 인덱스, 위치, 데이터 값을 저장하는데 활용된다.
- 언제나 동일한 해시값 리턴하고, index를 알면 빠른 데이터 검색이 가능해진다.
- 해시테이블의 시간복잡도 O(1)
- 이진탐색트리는 O(logN)
해시 함수(Hash Function)
- 임의의 데이터를 고정된 길이의 값으로 리턴해주는 함수
- 해시 함수는 입력 받은 데이터를 해시 값으로 출력시키는 알고리즘을 말한다.
- 출력된 해시 값은 알고리즘에 따라 다양한 결과를 보인다.
- 함수는 목적에 맞게 설계되며 자료구조, 캐시, 검색, 에러 검출, 암호 등으로 유용하게 사용된다.
int hashFuncion(string key){
return (int)(key[0]) % size; // 나머지 연산
}- 입력받는 키에서 문자열의 0번에 해당하는 문자를 정수화하여 해시 테이블의 크기만큼 나누고, 나머지를 변환하는 함수이다.
- 이렇게 반환된 값은 배열의 인덱스가 되고, 해당 인덱스에 맞게 저장을 할 수 있게 되는 것
- 함수의 로직은 단순할 수도 있고, 복잡할 수도 있다.
해시 테이블(Hash Table)
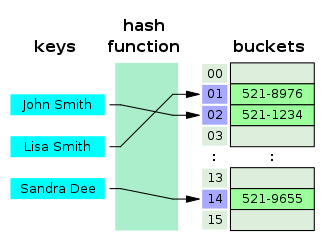
- 키 값의 연산에 의해 직접 접근이 가능한 데이터 구조
- 해시 테이블(Hash table)은 키와 값을 함께 저장해 둔 데이터 구조이다.
- 이는 데이터가 행과 열로 구성된 표에 저장되는 것과 유사하다.
- 테이블에 데이터를 저장할 때 위치는 무작위로 지정되어 작성된다.
- 따라서 중간에 여유 공간이 발생할 수 있다.
- 추가 용어
- 버킷(bucket) : 하나의 주소를 갖는 파일의 한 구역, 버킷의 크기는 같은 주소에 포함될 수 있는 레코드 수
- 슬롯(slot) : 한 개의 레코드를 저장할 수 있는 공간, 한 버킷 안에 여러 개의 슬롯이 있음
해싱(Hashing)
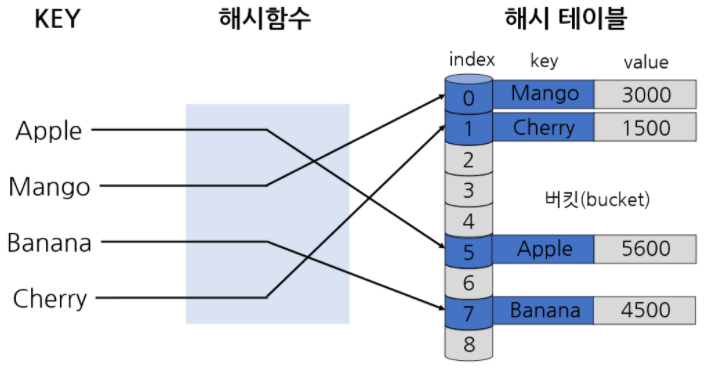
- 해싱은 해시 함수에서 해시를 출력하고, 해시 테이블에 저장하는 과정까지의 행위를 말한다.
충돌 문제
- 데이터가 많아지게 된다면 다른 데이터임에도 해시 함수에 의해 같은 해시 값이 반환되어 충돌이 발생함
- 그럼에도 해시 함수를 사용하는 이유
- 적은 자원으로 많은 데이터를 효율적으로 관리하기 위해
- 하드디스크나, 클라우드에 존재하는 무한한 데이터들을 유한한 개수의 해시값으로 매핑하면 작은 메모리로도 프로세스 관리가 가능해진다.
해결 방법
- 체이닝 : 연결리스트로 노드를 계속 추가해나가는 방식
- 제한 없이 계속 연결 가능, 하지만 메모리 문제가 발생할 수 있음
- Open Addressing : 해시 함수로 얻은 주소가 아닌 다른 주소에 데이터를 저장할 수 있도록 허용
- 해당 키 값에 저장되어있으면 다음 주소에 저장
- 선형 탐사 : 정해진 고정 폭으로 옮겨 해시값의 중복을 피함
- 제곱 탐사 : 정해진 고정 폭을 제곱수로 옮겨 해시값의 중복을 피함
장단점
장점
- 데이터 저장 / 읽기 속도가 빠름(검색 속도가 빠름)
- 해시는 키에 대한 데이터가 있는지 확인이 쉬움
단점
- 일반적으로 저장공간이 많이 필요
- 여러 키에 해당하는 주소(인덱스)가 동일한 경우 충돌을 해결하기 위한 별도 자료구조 필요
해시 구현
#include<iostream>
#include<string>
using namespace std;
class Slot{
public:
string value;
Slot() : Slot(""){}
Slot(string value) : value(value){}
};
class Hash{
private:
Slot** hashTable;
int size;
public:
Hash(int size){
this->size = size;
hashTable = new Slot *[size];
for(int i = 0;i<size;i++)
hashTable[i] = NULL;
}
~Hash(){
for(int i = 0;i<size;i++)
delete hashTable[i];
delete[] hashTable;
}
int hashFuncion(string key){
return (int)(key[0]) % size; // 나머지 연산
}
bool saveData(string key, string value){
int address = hashFuncion(key);
if(hashTable[address] != NULL){
hashTable[address]->value = value;
}
else{
hashTable[address] = new Slot(value);
}
return true;
}
string getData(string key){
int address = hashFuncion(key);
if(hashTable[address] != NULL){
return hashTable[address]->value;
}
else{
return "Not Found";
}
}
};
int main(){
Hash myHash(20);
myHash.saveData("Lee", "30000");
myHash.saveData("James", "15000");
myHash.saveData("Denny", "5000");
cout << myHash.getData("Lee") << std::endl;
cout << myHash.getData("James") << std::endl;
cout << myHash.getData("Denny") << std::endl;
return 0;
}
출처
[자료구조] 해시(HASH) 알아보기
안녕하세요!? 이번 게시글에서는 자료구조 중 해시에 대해서 정리하도록 하겠습니다. 해시는 저장 또는 검색 등에서 자주 활용되는 자료구조입니다. 정확하게는 특정한 함수(알고리즘)를 통해
kang-james.tistory.com
https://github.com/gyoogle/tech-interview-for-developer
GitHub - gyoogle/tech-interview-for-developer: 👶🏻 신입 개발자 전공 지식 & 기술 면접 백과사전 📖
👶🏻 신입 개발자 전공 지식 & 기술 면접 백과사전 📖. Contribute to gyoogle/tech-interview-for-developer development by creating an account on GitHub.
github.com
'CS > Data Structure' 카테고리의 다른 글
| [Data Structure] Trie (0) | 2024.04.03 |
|---|---|
| [Data Structure] B-Tree&B+Tree (0) | 2024.04.03 |
| [Data Structure] Binary Search Tree (1) | 2024.03.31 |
| [Data Structure] Tree (0) | 2024.03.31 |
| [Data Structure] Heap (0) | 2024.03.31 |
Hash(해시)?
- 해시는 입력된 데이터를 고정된 길이의 데이터로 변환 값을 말한다.
- 데이터를 효율적으로 관리하기 위해, 임의의 길이 데이터를 고정된 길이의 데이터로 매핑하는 것
- 해시 함수를 구현하여 데이터 값을 해시 값으로 매핑한다.
- 데이터가 많아지면, 다른 데이터가 같은 해시 값으로 충돌나는 현상이 발생함
- collision 현상
- 정수로 변환된 해시는 배열의 인덱스, 위치, 데이터 값을 저장하는데 활용된다.
- 언제나 동일한 해시값 리턴하고, index를 알면 빠른 데이터 검색이 가능해진다.
- 해시테이블의 시간복잡도 O(1)
- 이진탐색트리는 O(logN)
해시 함수(Hash Function)
- 임의의 데이터를 고정된 길이의 값으로 리턴해주는 함수
- 해시 함수는 입력 받은 데이터를 해시 값으로 출력시키는 알고리즘을 말한다.
- 출력된 해시 값은 알고리즘에 따라 다양한 결과를 보인다.
- 함수는 목적에 맞게 설계되며 자료구조, 캐시, 검색, 에러 검출, 암호 등으로 유용하게 사용된다.
int hashFuncion(string key){
return (int)(key[0]) % size; // 나머지 연산
}- 입력받는 키에서 문자열의 0번에 해당하는 문자를 정수화하여 해시 테이블의 크기만큼 나누고, 나머지를 변환하는 함수이다.
- 이렇게 반환된 값은 배열의 인덱스가 되고, 해당 인덱스에 맞게 저장을 할 수 있게 되는 것
- 함수의 로직은 단순할 수도 있고, 복잡할 수도 있다.
해시 테이블(Hash Table)
- 키 값의 연산에 의해 직접 접근이 가능한 데이터 구조
- 해시 테이블(Hash table)은 키와 값을 함께 저장해 둔 데이터 구조이다.
- 이는 데이터가 행과 열로 구성된 표에 저장되는 것과 유사하다.
- 테이블에 데이터를 저장할 때 위치는 무작위로 지정되어 작성된다.
- 따라서 중간에 여유 공간이 발생할 수 있다.
- 추가 용어
- 버킷(bucket) : 하나의 주소를 갖는 파일의 한 구역, 버킷의 크기는 같은 주소에 포함될 수 있는 레코드 수
- 슬롯(slot) : 한 개의 레코드를 저장할 수 있는 공간, 한 버킷 안에 여러 개의 슬롯이 있음
해싱(Hashing)
- 해싱은 해시 함수에서 해시를 출력하고, 해시 테이블에 저장하는 과정까지의 행위를 말한다.
충돌 문제
- 데이터가 많아지게 된다면 다른 데이터임에도 해시 함수에 의해 같은 해시 값이 반환되어 충돌이 발생함
- 그럼에도 해시 함수를 사용하는 이유
- 적은 자원으로 많은 데이터를 효율적으로 관리하기 위해
- 하드디스크나, 클라우드에 존재하는 무한한 데이터들을 유한한 개수의 해시값으로 매핑하면 작은 메모리로도 프로세스 관리가 가능해진다.
해결 방법
- 체이닝 : 연결리스트로 노드를 계속 추가해나가는 방식
- 제한 없이 계속 연결 가능, 하지만 메모리 문제가 발생할 수 있음
- Open Addressing : 해시 함수로 얻은 주소가 아닌 다른 주소에 데이터를 저장할 수 있도록 허용
- 해당 키 값에 저장되어있으면 다음 주소에 저장
- 선형 탐사 : 정해진 고정 폭으로 옮겨 해시값의 중복을 피함
- 제곱 탐사 : 정해진 고정 폭을 제곱수로 옮겨 해시값의 중복을 피함
장단점
장점
- 데이터 저장 / 읽기 속도가 빠름(검색 속도가 빠름)
- 해시는 키에 대한 데이터가 있는지 확인이 쉬움
단점
- 일반적으로 저장공간이 많이 필요
- 여러 키에 해당하는 주소(인덱스)가 동일한 경우 충돌을 해결하기 위한 별도 자료구조 필요
해시 구현
#include<iostream>
#include<string>
using namespace std;
class Slot{
public:
string value;
Slot() : Slot(""){}
Slot(string value) : value(value){}
};
class Hash{
private:
Slot** hashTable;
int size;
public:
Hash(int size){
this->size = size;
hashTable = new Slot *[size];
for(int i = 0;i<size;i++)
hashTable[i] = NULL;
}
~Hash(){
for(int i = 0;i<size;i++)
delete hashTable[i];
delete[] hashTable;
}
int hashFuncion(string key){
return (int)(key[0]) % size; // 나머지 연산
}
bool saveData(string key, string value){
int address = hashFuncion(key);
if(hashTable[address] != NULL){
hashTable[address]->value = value;
}
else{
hashTable[address] = new Slot(value);
}
return true;
}
string getData(string key){
int address = hashFuncion(key);
if(hashTable[address] != NULL){
return hashTable[address]->value;
}
else{
return "Not Found";
}
}
};
int main(){
Hash myHash(20);
myHash.saveData("Lee", "30000");
myHash.saveData("James", "15000");
myHash.saveData("Denny", "5000");
cout << myHash.getData("Lee") << std::endl;
cout << myHash.getData("James") << std::endl;
cout << myHash.getData("Denny") << std::endl;
return 0;
}
출처
[자료구조] 해시(HASH) 알아보기
안녕하세요!? 이번 게시글에서는 자료구조 중 해시에 대해서 정리하도록 하겠습니다. 해시는 저장 또는 검색 등에서 자주 활용되는 자료구조입니다. 정확하게는 특정한 함수(알고리즘)를 통해
kang-james.tistory.com
https://github.com/gyoogle/tech-interview-for-developer
GitHub - gyoogle/tech-interview-for-developer: 👶🏻 신입 개발자 전공 지식 & 기술 면접 백과사전 📖
👶🏻 신입 개발자 전공 지식 & 기술 면접 백과사전 📖. Contribute to gyoogle/tech-interview-for-developer development by creating an account on GitHub.
github.com
'CS > Data Structure' 카테고리의 다른 글
| [Data Structure] Trie (0) | 2024.04.03 |
|---|---|
| [Data Structure] B-Tree&B+Tree (0) | 2024.04.03 |
| [Data Structure] Binary Search Tree (1) | 2024.03.31 |
| [Data Structure] Tree (0) | 2024.03.31 |
| [Data Structure] Heap (0) | 2024.03.31 |