
1. 다익스트라 알고리즘?
- 다익스트라 알고리즘은 최소거리를 구할 때 사용하는 알고리즘이다.
- 다익스트라는 시작 노드로부터 모든 노드까지의 최소 거리를 구해준다.
- 다익스트라를 구현하기 위해서는 비용 배열, 방문 배열, 시작점에서 각노드까지의 비용 배열이 필요하다.
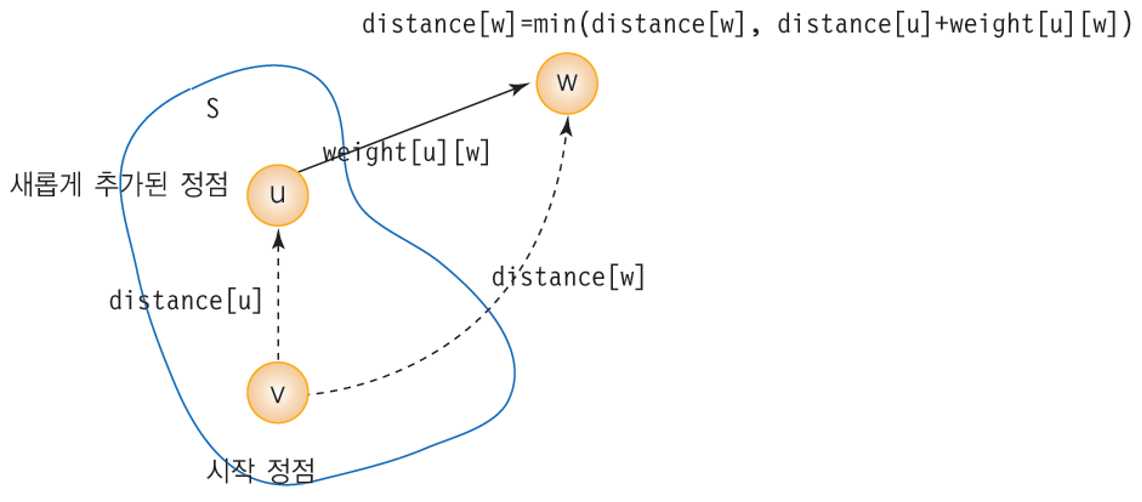
- weight 배열의 값을 통해 노드간의 연결을 판단한다.
- 특정 값이 있다면 연결되어 있다는 뜻이다.
- INF이면 연결되지 않았다는 뜻이다.
- weight 배열을 통해 단방향 노드나 양방향 노드로 만들 수 있다.
2. 다익스트라 알고리즘 구현
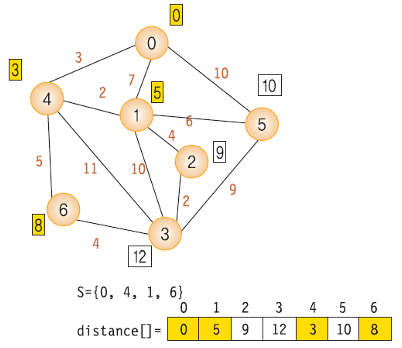
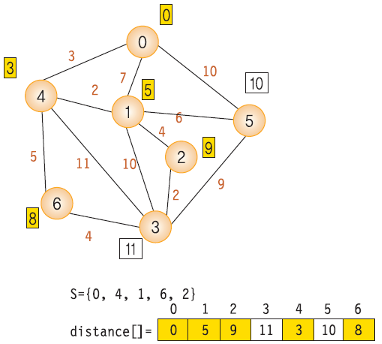
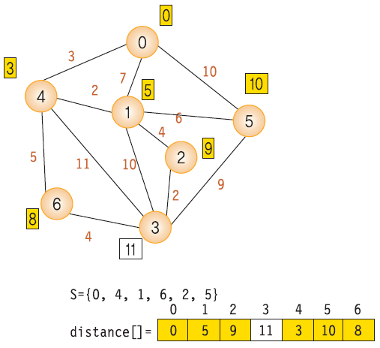
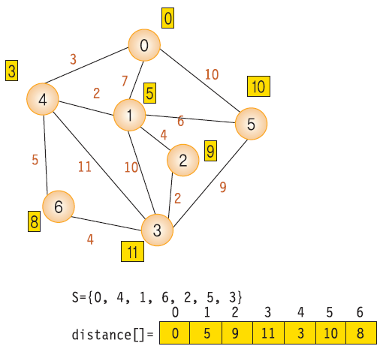
- 다익스트라 알고리즘의 순서는 다음과 같다.
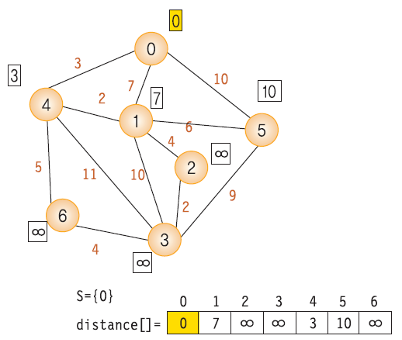
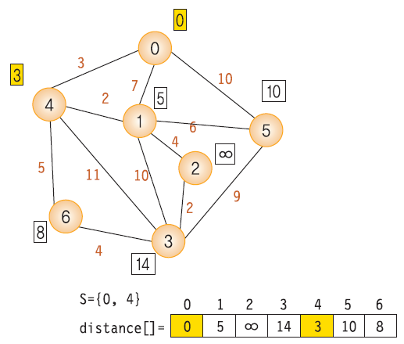
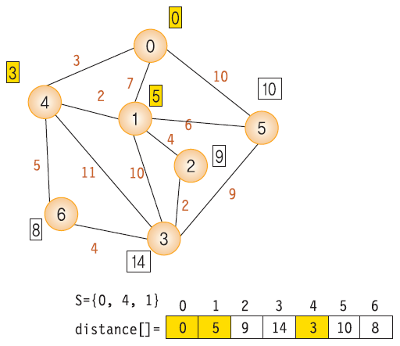
- dist 배열의 값을 weight[시작 노드]의 값으로 초기화
- 시작점을 방문 표시
- dist 배열에서 최소 비용 노드를 찾고 방문 처리. 이때 이미 방문한 노드는 무시
- 최소 비용 노드를 거쳐갈지 고려해서 dist 배열을 갱신. 이때 이미 방문한 노드는 무시
- 모든 노드를 방문할때까지 3~4 반복
- 위 방법을 한문장으로 정리하면 "방문하지 않은 노드 중 가장 작은 dist 값을 가진 노드를 방문하고, 그 노드와 연결된 다른 노드까지의 거리를 계산한다." 이다.
 |
 |
 |
 |
 |
 |
 |
이를 코드로 구현하면 아래와 같다.
#include<iostream>
#define INF 100000000
#define N 7
using namespace std;
int weight[N][N] = { {0, 7, INF, INF, 3, 10 ,INF},
{7, 0, 4, 10, 2, 6, INF},
{INF, 4, 0, 2, INF, INF, INF},
{INF, 10, 2, 0, 11, 9, 4},
{3, 2, INF, 11, 0, INF , 5},
{10, 6, INF, 9, INF, 0, INF},
{INF, INF, INF, 4, 5, INF, 0} };
bool visit[N];
int dist[N];
int min_node;
int getSmallNode() {
int min = INF;
int minpos = 0;
for (int i = 0; i < N; i++) {
if (dist[i] < min && !visit[i]) {
min = dist[i];
minpos = i;
}
}
return minpos;
}
void dijkstra(int start) {
for (int i = 0; i < N; i++)
dist[i] = weight[start][i];
visit[start] = true;
for (int i = 0; i < N - 1; i++) {
min_node = getSmallNode(); // 최소비용노드 탐색
visit[min_node] = true; // 최소비용노드 방문 처리
for (int j = 0; j < N; j++) {
// 방문하지 않은 노드 중에, 시작점이 최소 비용노드를 경유하는게
// 더 가까우면 값 갱신
if (!visit[j])
if (dist[min_node] + weight[min_node][j] < dist[j])
dist[j] = dist[min_node] + weight[min_node][j];
}
}
}
int main() {
dijkstra(0);
for (int i = 0; i < N; i++)
cout << dist[i] << ' ';
return 0;
}- 위 방식으로 구현한 다익스트라 알고리즘의 시간 복잡도는 O(V^2)이 된다.
- V는 노드의 수
- N-1번 반복과 최소 비용 노드를 찾을 때 N번 반복이 있다.
- 노드의 계수가 많아질 수록 비효율적인 알고리즘이 된다.
- 이러한 높은 시간 복잡도를 개선하기 위해 우선순위 큐를 활용한 다익스트라 알고리즘을 사용해야한다.
3. 우선순위 큐를 통해 구현한 다익스트라
- 우선순위 큐를 사용해서 다익스트라를 구현 시 최소비용 노드를 구하는 함수를 우선순위 큐가 대신하게 된다.
- 또한 visit 배열의 필요도 사라지게된다.
- 구현 시 필요한 배열은 아래와 같다.
- 노드 정보 벡터 nodes : 각 노드마다 연결되어 있는 모든 노드와 비용 정보를 나타낸다.
- 시작점에서 각 노드까지의 비용 배열 dist
- 우선순위 큐 pq : 간선 정보를 저장
- 알고리즘은 아래와 같다.
- dist 배열을 모두 INF로 초기화하고 노드 정보를 모두 입력
- dist[시작노드]를 0으로 값 갱신
- pq에 {0, 목적지 노드}를 push
- pq가 empty일 때 까지 반복
- pq.front에 대해
- dist[노드] < 비용 이면 무시 -> 이미 노드까지의 최소 비용을 알고 있다는 뜻
- 노드의 모든 인접 노드 검사 -> 자신을 거쳐가는 것이 빠르면 비용 갱신 후 {갱신한 비용, 인접 노드}를 push
- 2번 다익스트라 알고리즘 구현에서 보여준 예시를 우선순위 큐를 통해 구현하면 아래와 같다.
#include<iostream>
#include <vector>
#include <queue>
#define INF 100000000
#define N 7
using namespace std;
vector<pair<int, int>> nodes[N];
int dist[N];
void dijkstra(int start) {
priority_queue<pair<int, int>> pq;
pq.push({ 0,start });
dist[start] = 0;
while (!pq.empty()) {
int cost = -pq.top().first; // 우선 순위 큐는 내림차순 정렬이 디폴트
int here = pq.top().second;
pq.pop();
// 이미 최단 거리 정보가 있으면 무시
if (dist[here] < cost) continue;
for (int i = 0; i < nodes[here].size(); i++) {
int vist_cost = cost + nodes[here][i].first;
// here를 경유해서 가는게 더 빠르면 dist 갱신 후 push
if (vist_cost < dist[nodes[here][i].second]) {
dist[nodes[here][i].second] = vist_cost;
pq.push({ -vist_cost,nodes[here][i].second });
// 내림차순 정렬이라서 최소 값이 항상 앞에 오도록 음수 처리
}
}
}
}
int main() {
for (int i = 0; i < N; i++)
dist[i] = INF;
nodes[0].push_back({ 7,1 }); nodes[0].push_back({ 3,4 });
nodes[0].push_back({ 10,5 });
nodes[1].push_back({ 7,0 }); nodes[1].push_back({ 4,2 });
nodes[1].push_back({ 10,3 }); nodes[1].push_back({ 2,4 });
nodes[1].push_back({ 6,5 });
nodes[2].push_back({ 4,1 }); nodes[2].push_back({ 2,3 });
nodes[3].push_back({ 10,1 }); nodes[3].push_back({ 2,2 });
nodes[3].push_back({ 11,4 }); nodes[3].push_back({ 9,5 });
nodes[3].push_back({ 4,6 });
nodes[4].push_back({ 3,0 }); nodes[4].push_back({ 2,1 });
nodes[4].push_back({ 11,3 }); nodes[4].push_back({ 5,6 });
nodes[5].push_back({ 10,0 }); nodes[5].push_back({ 6,1 });
nodes[5].push_back({ 9,3 });
nodes[6].push_back({ 4,3 }); nodes[6].push_back({ 5,4 });
dijkstra(0);
for (int i = 0; i < N; i++)
cout << dist[i] << ' ';
return 0;
}- 위 방식으로 구현한 다익스트라 알고리즘의 시간 복잡도는 O(Elog E) 이다.
- E는 에지의 개수이다.
- log 의 시간 복잡도를 가지는 이유는 우선순위큐가 힙 자료 구조를 활용해서 구현되었기 때문이다.
- 큐의 최악의 크기는 에지의 개수의 E와 같고, E개를 계속해서 탐색하고 삭제하기 때문에 Elog E의 시간복잡도를 가진다.
4. 다익스트라의 한계
- 다익스트라 알고리즘은 노드의 재방문을 허용하지 않기 때문에 음수 간선이 존재하는 경우 사용할 수 없다.
- 음수 간선이 존재하면 재 방문을 고려해야하는데 이는 다익스트라 알고리즘에 위배되는 행위이다.
- 다익스트라 알고리즘은 최소 거리를 누적하여 더해가는 방식이기 때문에 모든 가중치가 0 이상임이 보장되어야 그 값이 최소 임을 보장할 수 있다.
- 음수 가중치가 존재하면 0이상임이 보장되지 않아 방문한 노드의 비용이 최소임을 알 수 없다.
- 따라서 음수 간선이 존재하면 밸만-포드 알고리즘이나 SPFA 알고리즘을 활용해야한다.
출처
https://charles098.tistory.com/11
[C++] 다익스트라(Dijkstra)
1. 다익스트라의 구성 최소 거리를 구할때 사용하는 대표적인 알고리즘 '다익스트라'에 대해 알아보자. 다익스트라 알고리즘은 시작점으로부터 모든 노드까지의 최소거리를 구해준다. 다익스트
charles098.tistory.com
'Algorithm' 카테고리의 다른 글
| [Algorithm] KMP 알고리즘 (0) | 2024.10.22 |
|---|---|
| [Algorithm] 다익스트라 알고리즘 (1) | 2024.09.10 |
| <algorithm> Red-Black Tree (RB Tree) (0) | 2024.01.26 |
| <algorithm> 그리디 알고리즘 (1) | 2023.11.22 |
| <algorithm> Dynamic Programming (1) | 2023.11.06 |