
Unordered Map의 특성
- 표준이 아닌 hash map 대신 unordered_map을 표준으로 정의
- 마이크로소프트에서도 hash_map보다는 unordered_map을 권장하고 API 문서도 제공
- hash map은 성능이 보장되지 않기 때문에 권장되지 않는다.
- 순서있게 자료를 유지하지 않고, 입력받은 Data를 테이블에 저장한다.
- 입력받은 Data를 Hash 함수를 통해 Hash Table에 저장하는 것이 핵심
- Key-Value 쌍으로 데이터를 저장하고, Key를 통해 Data를 빠르게 찾을 수 있다.
Hash 함수를 사용하는 이유
- 많은 양의 Data를 저장할 때, 검색 속도를 O(1) 수준으로 만들어 버리는 강력한 솔루션이다.
- 시퀀스 기반의 Vector와 list 등의 검색 속도는 데이터 양에 비례하는 O(N)임
- input으로 Key-Value가 들어오면, hash function을 통해 새로 만든 index를 통해 hash table에 Value를 저
- hash table은 배열 기반으로 저장되어 있기에 Key만 알면 Value를 바로 찾을 수 있다.
Unordered Map의 내부 동작
- Unordered Map은 Key를 통한 Value의 접근이 빠르다는 특징을 가지고 있다.
- 이는 hash에 의한 특징이며 hash function을 통해 데이터를 특정한 index로 변환하는 특징을 가짐
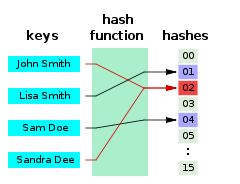
- hash 연산을 하는 hash function의 알고리즘은 MD5, SHA 등이 있다.
- unordered map은 해시 함수를 통해 Key를 특정 값으로 변환하여 Value를 저장할 공간의 index로 사용한다.
- 저장 공간은 bucket(버킷), slot(슬롯)으로 부른다.
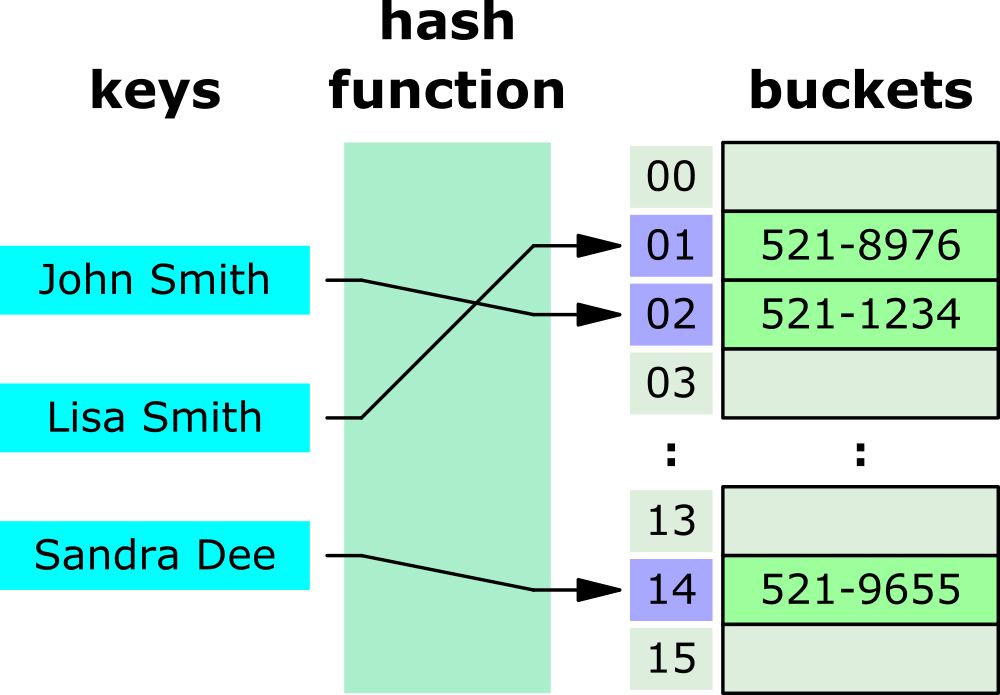
- "Sandra Dee"라는 데이터를 동일한 hash function에 넣으면 항상 14라는 데이터를 반환한다.
- 이는 Key를 통해 Value가 저장된 공간에 상수 시간에 접근할 수 있다는 것을 의미한다.
- 즉, O(1)의 시간 복잡도를 가진다는 의미이다.
- Key-Value의 쌍이 10개든 100개든 데이터의 양에 상관 없이 해쉬 함수를 통해 Value가 저장된 공간의 index를 알 수 있다.
- 해시 함수가 아닌 Key를 직접 비교하며 Value를 찾게 되면 그림에서는 15번의 연산이 필요할 것이다.
- 단, 역은 성립하지 않아 해시값을 통해 "Sandra Dee"라는 Key 값을 찾을 수 없다.
해시 충돌
- Key는 무한하지만 Bucket의 크기는 유한하다는 문제에 의해 발생한다.
- Key는 다르지만 확률상 해시 함수가 동일한 값을 반환할 수 있는 문제에 의해 발생할 수도 있다.
- 동일한 해시값을 받게된다면, Value를 저장할 Bucket의 Index도 동일하다는 문제를 가지게 된다.
- 다른 key 값으로 동일한 해시값이 나오는 걸 해시 충돌(Hash collision)이라고 한다.
- 해시 충돌은 Unordered Map의 성능을 떨어뜨리는 주범이된다.
- 해시 충돌은 hash function이 해결해야할 문제이다.
- 해시 충돌은 불가피하며, 단지 확률을 낮춰 충돌을 최대한 피하는 것이 최선의 방법이다.
충돌 대안 1 . 체이닝(Chaning)
- 해시 충돌이 발생해 동일한 index가 나오면 해당 index에 추가로 이어서 저장하는 방법

- 152번 index에 이미 "John Smith"-"521-1234"라는 쌍이 저장되어 있다고 가정
- "Sandra Dee"-"521-9655" 쌍을 저장하고 싶지만 해시 함수에 Key를 넣으니 152번 index가 반환되어 충돌이 발생
- Value가 저장되는 공간을 Vector와 같은 가변 배열로 구현하여, 충돌 시 기존 Value에 이어 다음 요소를 추가하면 충돌을 해결할 수 있다.
- 위 방법을 연쇄적으로 연결한다고 하여 체이닝(Chaining)이라고 부른다.
- "Sandra Dee"의 Value인 "521-9655"에 접근하기 위해 해싱을 통해 index를 얻고, "521-9655"가 나올 때 까지 순차적으로 탐색해야할 것
- 이는 Bucket의 index에는 상수 시간으로 접근하지만, 해시 충돌에 의해 요소가 여러개의 경우 일치하는 Value를 찾기 위해 요소를 하나씩 탐색해야한다.
- 최악의 경우 선형 시간이 소요될 것이다.
- 그러나 Bucket을 이렇게 설계하지 않고 다른 방식으로 해시 충돌을 해소하기 때문에 시간 복잡도는 O(1)이라고 한다.
충돌 대안 2. 개방 번지화(Opening Addressing)
- 해시 충돌이 발생하였을 때 그 결과(index)를 버리고, 비어있는 다른 index에 Value를 할당하는 방법
- 이 방법은 매번 동일한 결과를 얻기 위해 규칙이 존재한다.

- "Sandra Dee"는 hash function에 의해 152번 index를 받았지만 153번 index에 Value가 저장되었다.
- "Ted Baker"는 hash function에 의해 153번 index를 받았지만 154번 index에 Value가 저장되었다.

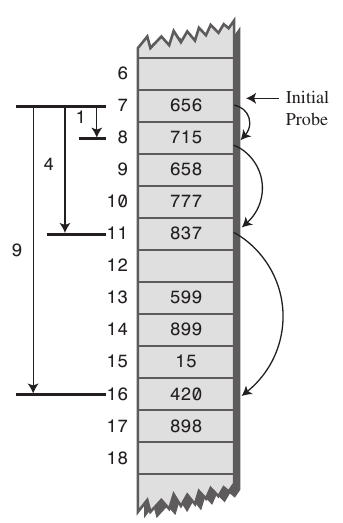
- Opening Addressing에 비어있는 index를 탐색하는 방법은 여러개가 있다.
- 선형 탐사(Linear Probing)
- 고정된 index로 탐사한다.
- 위 Bucket에서 152번에 충돌이 발생한 경우 바로 다음 index를 확인한다.
- 이 방법은 Value가 특정 구간에 밀집되는 클러스터(Cluster) 현상이 발생하기 쉽다.
- 따라서 많은 데이터가 밀집되어 있는 경우 탐색 시간이 길어진다는 단점이 있다.
- 제곱 탐사(Quadratic Probing)
- 선형 탐사와 유사하지만 index를 단순히 선형으로 증가시키는 것이 아닌 이차식을 통해 index를 구해 한 곳에 데이터가 집중되지 않도록 한다.
- 하지만 탐사를 하여도 같은 해시값이 나올 경우 동일한 과정을 거치기 때문에 2차 클러스터가 발생할 수 있다.
- 이중 해싱(Double Hashing)
- 해시 충돌이 발생한 경우 다른 해시 함수를 통해 증가폭을 구한다.
- 증가폭만큼 index를 증가시켜 비어있는 곳을 탐사하는 것이 이중 핵심의 특징이다.
- 선형 탐사(Linear Probing)
해시 충돌 최소화 방법
- 해시 충돌을 최소화 하는 것이 대안을 찾는 방법보다 중요하다,
- 해시 충돌을 최소화하는 것은 여러가지 방법이 있다.
- 해시 함수를 제대로 설계하는 방법
- 잘 만들어진 해시 함수를 사용하는 것이 충돌을 최소화 하는 방법이다.
- 잘 설계하지 못한 해시 함수는 동일한 해시값을 반환할 확률이 높다.
- Bucket의 Size가 커야한다.
- 이상적인 Bucket의 Size는 들어오는 Key의 계수가 Bucket Size의 40% 정도일 때이다.
- Bucket의 크기가 10인데 Key가 20개인 경우 충돌이 발생할 것이다.
- Bucket의 크기를 소수(Prime Number)로 설계한다.
- 소수는 2, 3, 5, ... 등과 같은 1을 제외하고 1과 자신으로만 나누어지는 수를 의미한다.
- 수학적으로 이진수인 경우 소수가 어떤 계산으로부터 나올 확률이 훨신 적기 때문이다.
- 해시 함수를 제대로 설계하는 방법
- 위 방식을 사용하면 웬만하면 O(1)의 속도를 얻을 수 있다.
- 잘 만들어진 해시 함수의 예로는 djb2라는 해시 함수가 존재한다.
Unordered Map의 멤버 함수
|
begin
|
첫 번째 원소의 랜덤 접근 반복자를 리턴
|
|
clear
|
저장한 모든 원소를 삭제
|
|
empty
|
저장한 요소가 없으면 true 리턴
|
|
end
|
마지막 원소 다음의 반복자를 리턴
|
|
erase
|
특정 위치의 원소나 지정 범위의 원소들을 삭제
|
|
find
|
key와 연관된 원소의 반복자 리턴
|
|
count
|
Key와 연관된 원소의 반복자 리턴
find와 동일합니다.
|
|
insert
|
원소 추가
|
|
size
|
원소의 개수 리턴
|
|
rbegin
|
역방향으로 마지막 원소 다음의 반복자를 리턴
|
|
rend
|
역방향으로 마지막 원소 다음의 반복자를 리턴
|
|
swap
|
두 컨테이너의 내용을 바꿉니다.
|
|
operator[]
|
지정된 키가 있는 요소를 찾거나 삽입합니다.
|
- unordered_map의 멤버 함수는 map의 함수와 유사한 결과를 보인다.
Map vs Unordered_map
- 데이터의 크기가 적을 때는 map이 유리하고 아니면 unorderd_map이 유리하다.
- map은 크기가 커질 때마다 케시 미스의 영향을 받으므로 탐색할 때 여러 노드를 방문하기 때문이다.
- unordered_map의 성능은 해시 함수에 영향을 받는다.
- 해시 함수의 성능이 좋지 못하면 데이터가 고르게 분포되지 않고 충돌이 여러번 발생할 것이다.
- 충돌이 발생하면 연결리스트 기반으로 줄지어 데이터를 보관하기 때문에 검색 시 충돌이 발생한 만큼 순차적으로 확인해야함
- 문자열 키를 사용하는 경우 map이 unordered_map보다 탐색 성능의 우위를 가짐
- map은 RB(Red-Black) Tree를 기반으로 구현되어 있어 문자열 비교시 적은 비교 횟수를 필요로 하기 때문
- 문자열 길이가 길고, 데이터의 크기가 적은 경우 map을 사용하는 것이 유리함
출처
https://woo-dev.tistory.com/106
[C++] 해시맵(Hashmap)을 이해해보자 | std::unordered_map | 기술면접
해당 포스팅은 unordered_map 클래스 자체보단 해시맵/해시테이블에 대한 내용을 다룹니다. [기존의 STL std::map] C++ 11 이전의 기존 STL 컨테이너인 std::map은 요소가 자동으로 오름 차순으로 정렬되는
woo-dev.tistory.com
https://baeharam.netlify.app/posts/data%20structure/hash-table
[DS] 해쉬 테이블(Hash Table)이란? - 배하람의 블로그
해싱이란? (Hashing) 해싱이란 임의의 길이의 값을 해시함수(Hash Function)를 사용하여 고정된 크기의 값으로 변환하는 작업을 말한다. 그림 출처 위 그림에서 dog 라는 문자열을 해시함수를 이용해 새
baeharam.netlify.app
https://blog.naver.com/PostView.naver?blogId=do9562&logNo=221754890348
[C++] STL unordered_map
STL 네번째 시간입니다! 이번에는 unordered_map container에 대해서 알아봅시다. 참고한 서적: Thinki...
blog.naver.com
'C++' 카테고리의 다른 글
| <STL> List (0) | 2024.02.01 |
|---|---|
| <STL> Vector (0) | 2024.02.01 |
| <STL> map (0) | 2024.01.26 |
| <STL> unique 함수 (0) | 2023.10.03 |
| <STL> sort 함수 (0) | 2023.10.03 |